In the modern IT landscape, autoscaling is the holy grail. We design systems to treat servers as disposable commodities—spinning them up when demand spikes and terminating them the moment traffic drops. It is efficient, cost-effective, and resilient. Cloud-native architecture celebrates elasticity over permanence.
Lately, I’ve noticed organizations applying this same architectural pattern to people.
The logic looks sound on a spreadsheet: why invest in the vertical scaling of a veteran engineer—who is expensive and operating near human context and attention limits—when you can scale out with several freshers or short-term resources? Replace a perceived single point of failure with a resilient cluster. More nodes, more throughput.
This is not a critique of freshers. It is a critique of assuming all workloads are stateless.
Because any veteran systems architect knows: horizontal scaling only works when the nodes are truly interchangeable. And in the world of human expertise, they are not.
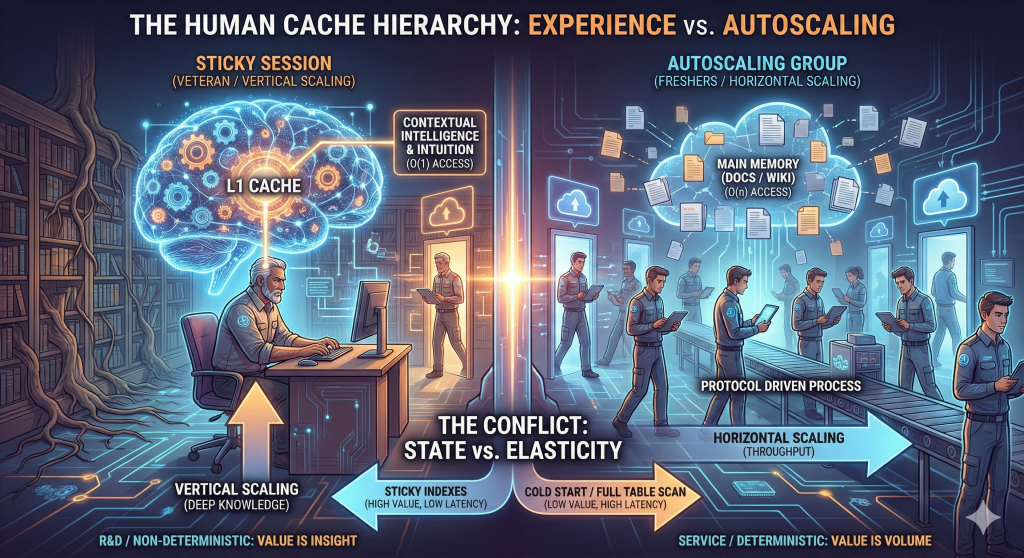
The Conflict: State vs. Elasticity
In distributed systems, session stickiness (session affinity) ensures that a user’s requests are routed to the same server because that server holds the interaction’s context—its state—in local memory.
This maps uncomfortably well to organizations:
- The Veteran is a “Sticky” Server.
They hold years of historical context, architectural rationale, failure patterns, and institutional memory in their head. - The Fresher is a “Stateless” Node.
They are eager, capable, and scalable—but they start with empty caches.
Organizations want elasticity: the ability to hire (scale out) and lay off (scale down) quickly in response to market conditions. To achieve this, they attempt to externalize all “state” from the veteran’s head into process documents, wikis, runbooks, and ISO standards.
The assumption is simple: once the state lives in the wiki (the Redis), the compute (the human) becomes disposable.
This is where the architecture breaks.
The Index vs. the Full Table Scan
The fatal flaw in replacing veterans with freshers is the belief that data availability equals query performance.
Yes, the answer may be written down. But finding the answer under pressure is a different problem.
When a production incident hits:
- The Fresher performs a full table scan.
They search documentation, read logs linearly, follow runbooks step by step, and experiment. This is an O(n) operation. As system complexity grows, time-to-resolution increases proportionally. - The Veteran performs an index seek.
Over years, they have built mental indexes—error signatures mapped to likely failure domains, subtle correlations, historical scars. They see an alert and jump directly to Sector 4, Row 12. This is an O(1) operation.
You can document the data.
You cannot document the index.
That index is not just memory—it is an evolved execution plan for navigating complexity.
The Tiered Cache Hierarchy: Why “Process” Alone Fails
Organizations love process because it promises standardization and control. Documentation is treated as the great equalizer—accessible to all, authoritative, and auditable.
But high-performance systems do not rely on a single memory tier.
They use a cache hierarchy:
- L1 Cache — Veteran Intuition
Ultra-fast, volatile, and physically bound to the core. It holds the hot context: why the system is misbehaving right now. L1 cannot be shared. - Main Memory — Documentation and Process
Larger, slower, often stale. Necessary, but not sufficient.
When you scale down a veteran, you are evicting the L1 cache. The organization is forced to fetch every instruction from main memory.
The result is latency.
Decisions that once took five minutes now take three days—documentation review, interpretation, meetings, alignment. The system hasn’t lost data. It has lost speed of thought.
The Cold Start Problem
In autoscaling groups, new instances suffer from cold starts. Until caches warm and execution paths optimize, performance is degraded.
A team composed entirely of short-tenure resources—gig workers, rapid churn hires, constant rotation—lives in a permanent cold start. Every incident pays the CPU tax of rediscovery.
The veteran is a hot server. Their internal query engine has been JIT-compiled against the quirks, edge cases, and failure modes of the environment.
You can spin up more instances.
You cannot fast-forward cache warmth.
Control Plane vs. Data Plane
This is where many organizations misapply cloud metaphors.
Freshers scale the data plane: execution, implementation, repeatable tasks. They are excellent at deterministic problems where the path from A to B is well defined.
Veterans anchor the control plane: diagnosis, prioritization, mental model selection, and asking the right questions when the problem is undefined.
You can autoscale the data plane.
You cannot autoscale the control plane without externalizing it first—and some parts of it resist externalization by nature.
A Fair Counterargument
The counterargument is reasonable: veterans can and should mentor, document, and automate themselves out of critical paths. Knowledge should not be hoarded. Bus factors matter. Organizations that depend on heroes are fragile.
All of this is true.
But there is a systems caveat: index creation is expensive and sequential. Teaching intuition, pattern recognition, and judgment is not a broadcast operation. It requires time, exposure, and shared failure. You can replicate data quickly. You cannot replicate access paths at the same rate.
Mentorship scales impact—but it does not eliminate the need for experienced control-plane nodes.
The Verdict: When to Stick and When to Scale
Autoscaling is not the enemy. Misclassification of workload is.
- Scale Out (Freshers) for deterministic, well-documented, repeatable problems.
- Stickiness (Veterans) for non-deterministic, novel, high-ambiguity situations where diagnosis matters more than execution.
To the veterans: your value is no longer just knowing the answer—it is the low-latency retrieval of the answer.
To organizations: you can autoscale your compute, but you cannot autoscale your control plane. If you drain all your sticky sessions, don’t be surprised when request latency spikes, incident budgets evaporate, and decision-making slows to a crawl.
Elasticity without state awareness is not resilience.
It is just churn with better tooling.
